xiaozhch5 opened a new issue, #6301: URL: https://github.com/apache/hudi/issues/6301
**Describe the problem you faced** When I use flink bulk_insert **batch** mode to load the data with 406,000 lines and 4 partitions from hdfs file to hudi, it almost impossible to insert the data. Flink spent 40+ mins to insert the data, but it eventually failed. 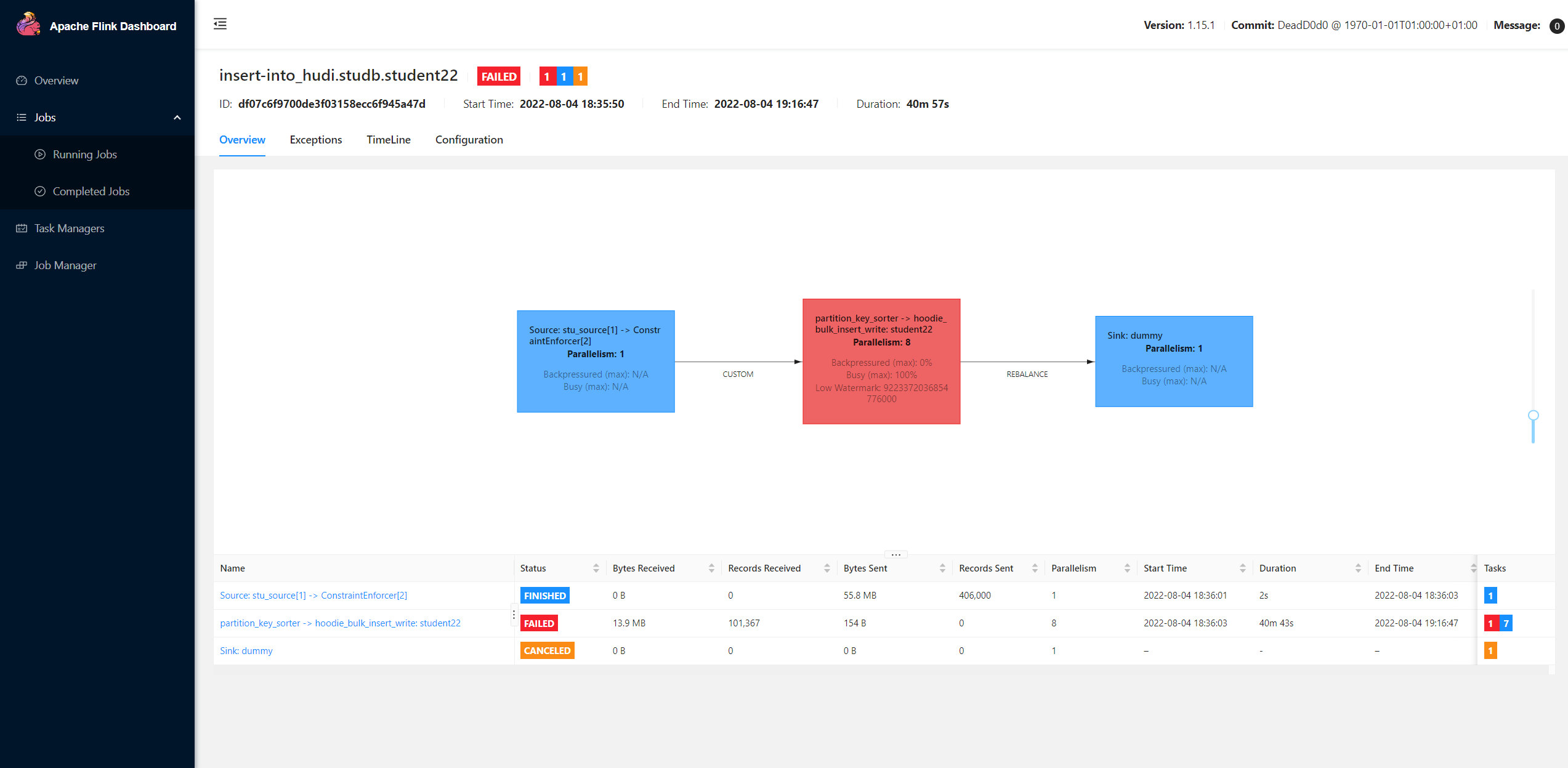 Also flink will create so many small parquet files. 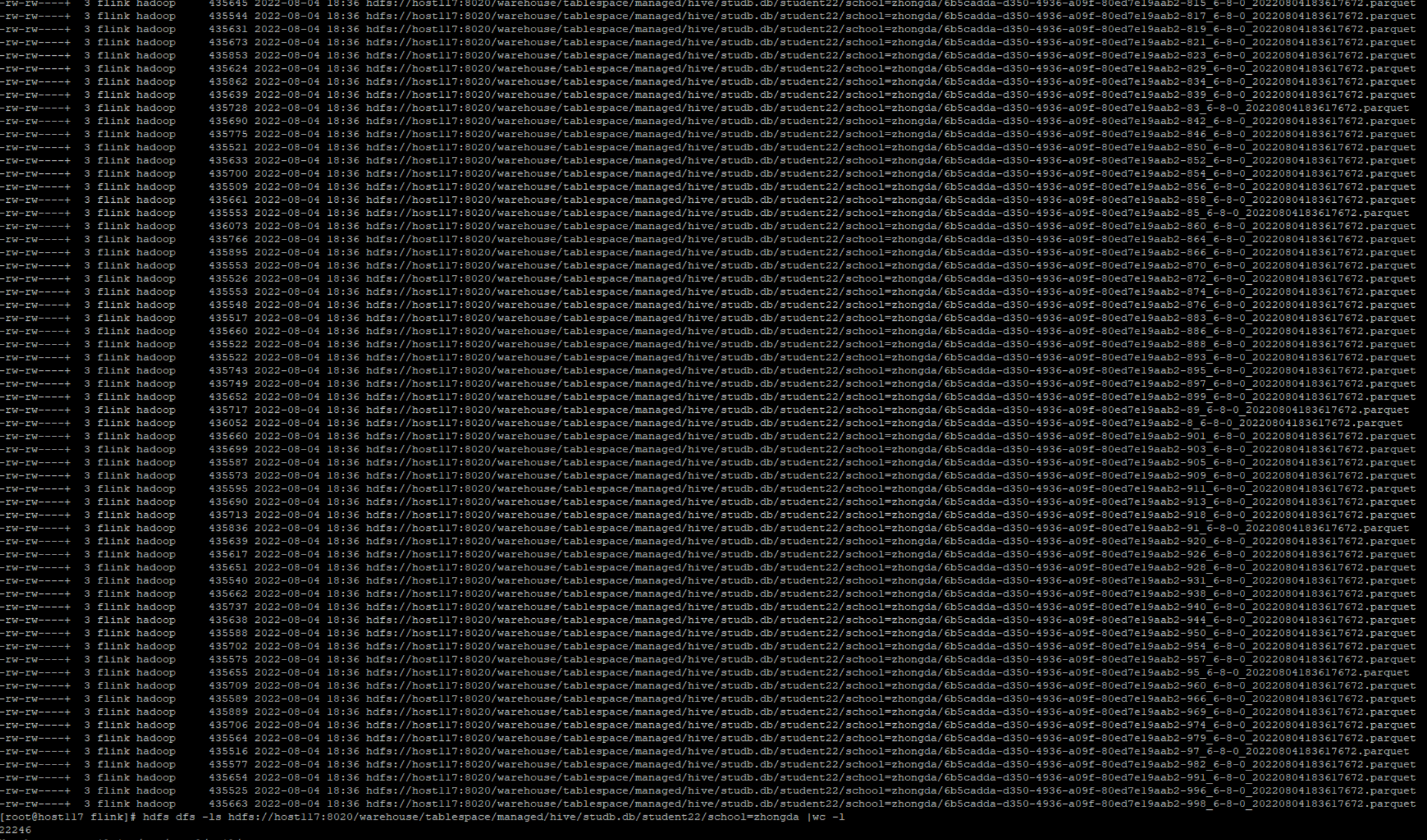 But if I use upsert mode with flink, it only spent about 53 seconds to upsert the data and only few log files. 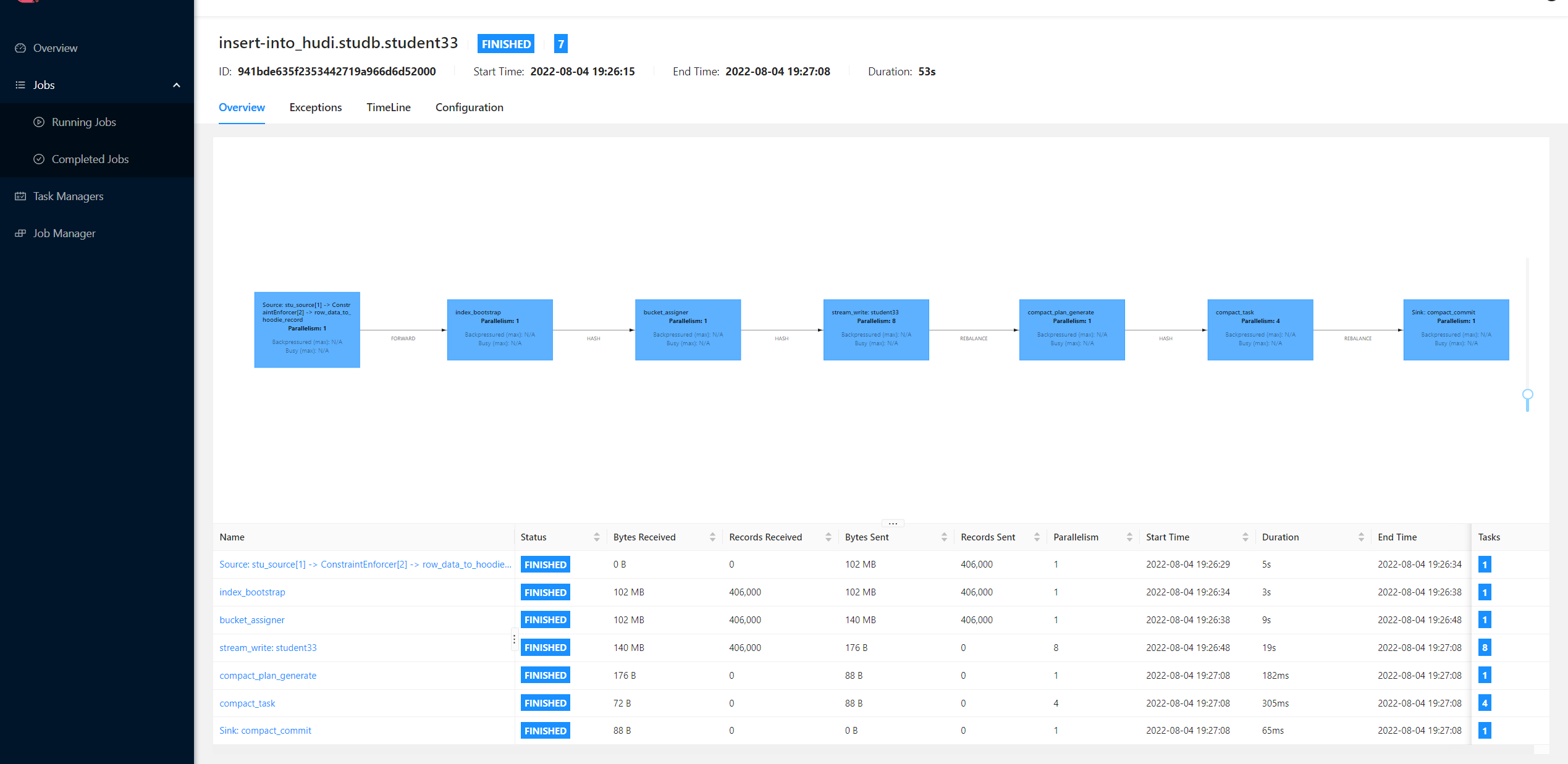  **To Reproduce** Steps to reproduce the behavior: 1. The data in hdfs is like below: ```txt 1,WLYzvkajXzdZKiotcK,zhongda,mike,82,43,67.36,18288287027,[email protected],192.168.186.144 3,WLYzvkajXzdZKiotcK,zhongda,huni,82,43,67.36,18288287027,[email protected],192.168.186.144 4,WLYzvkajXzdZKiotcK,beida,tomy,82,43,67.36,18288287027,[email protected],192.168.186.144 2,WLYzvkajXzdZKiotcK,xidian,tomy,82,43,67.36,18288287027,[email protected],192.168.186.144 6,NKcZrLTHw,huagong,huni,62,76,78.84,18088117352,[email protected],192.0.4.216 7,NKcZrLTHw,xidian,tony,62,76,78.84,18088117352,[email protected],192.0.4.216 5,NKcZrLTHw,beida,mike,62,76,78.84,18088117352,[email protected],192.0.4.216 8,NKcZrLTHw,zhongda,tomy,62,76,78.84,18088117352,[email protected],192.0.4.216 9,tX,huagong,tony,42,53,92.76,18765656706,[email protected],192.0.12.190 10,tX,xidian,tony,42,53,92.76,18765656706,[email protected],192.0.12.190 ``` 3. Full sql: **upsert mode** ```sql drop catalog if exists hudi; create catalog hudi with( 'type' = 'hudi', 'mode' = 'hms', 'hive.conf.dir'='/etc/hive/conf' ); create database if not exists hudi.studb; drop table if exists stu_source; create table stu_source ( id int, name string, school string, nickname string, age int, class_num int, score decimal(4, 2), phone bigint, email string, ip string, primary key (id) not enforced ) with ( 'connector' = 'filesystem', 'path' = 'hdfs://host117:8020/tmp/student', 'format' = 'csv' ); drop table if exists hudi.studb.student33; create table hudi.studb.student33 ( id int, name string, school string, nickname string, age int, class_num int, score decimal(4, 2), phone bigint, email string, ip string, primary key (id) not enforced ) partitioned by (school) with ( 'connector' = 'hudi', 'table.type' = 'MERGE_ON_READ', 'hoodie.datasource.write.hive_style_partitioning' = 'true', 'hoodie.datasource.write.recordkey.field' = 'id', 'hive_sync.enable' = 'false', 'write.operation' = 'upsert', 'write.tasks' = '8' ); insert into hudi.studb.student33 select * from stu_source; ``` **bulk_insert mode** ```sql drop catalog if exists hudi; create catalog hudi with( 'type' = 'hudi', 'mode' = 'hms', 'hive.conf.dir'='/etc/hive/conf' ); create database if not exists hudi.studb; drop table if exists stu_source; create table stu_source ( id int, name string, school string, nickname string, age int, class_num int, score decimal(4, 2), phone bigint, email string, ip string, primary key (id) not enforced ) with ( 'connector' = 'filesystem', 'path' = 'hdfs://host117:8020/tmp/student', 'format' = 'csv' ); drop table if exists hudi.studb.student22; create table hudi.studb.student22 ( id int, name string, school string, nickname string, age int, class_num int, score decimal(4, 2), phone bigint, email string, ip string, primary key (id) not enforced ) partitioned by (school) with ( 'connector' = 'hudi', 'table.type' = 'MERGE_ON_READ', 'hoodie.datasource.write.hive_style_partitioning' = 'true', 'hoodie.datasource.write.recordkey.field' = 'id', 'hive_sync.enable' = 'false', 'write.operation' = 'bulk_insert', 'write.tasks' = '8' ); insert into hudi.studb.student22 select * from stu_source; ``` **Expected behavior** If I use bulk_insert with flink, I may be fast to load the data from hdfs to hudi. **Environment Description** * Flink version: 1.15.1 * Hudi version : 0.12.0-rc1 * Spark version : * Hive version : 3.1.2 * Hadoop version : 3.2.0 * Storage (HDFS/S3/GCS..) : HDFS * Running on Docker? (yes/no) : **Stacktrace** There are so many logs in taskmanager like below: 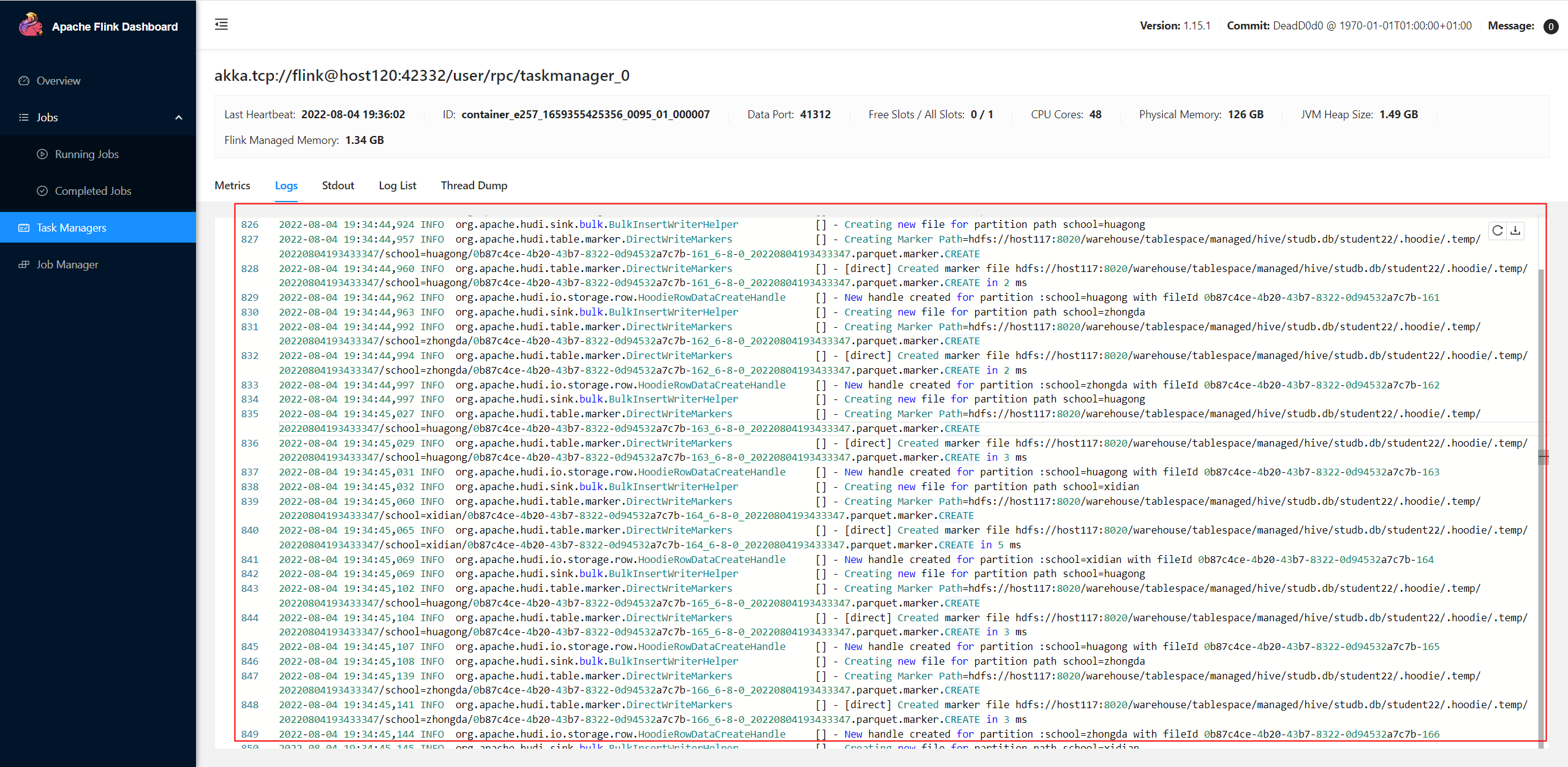 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}