glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1198302501
Providing Screenshots for spark UI
for the said command
`df=spark.read.json('s3://rz.auto.billing/RealTime/EXS.ResponseJSON/2022-07-12/*')
`

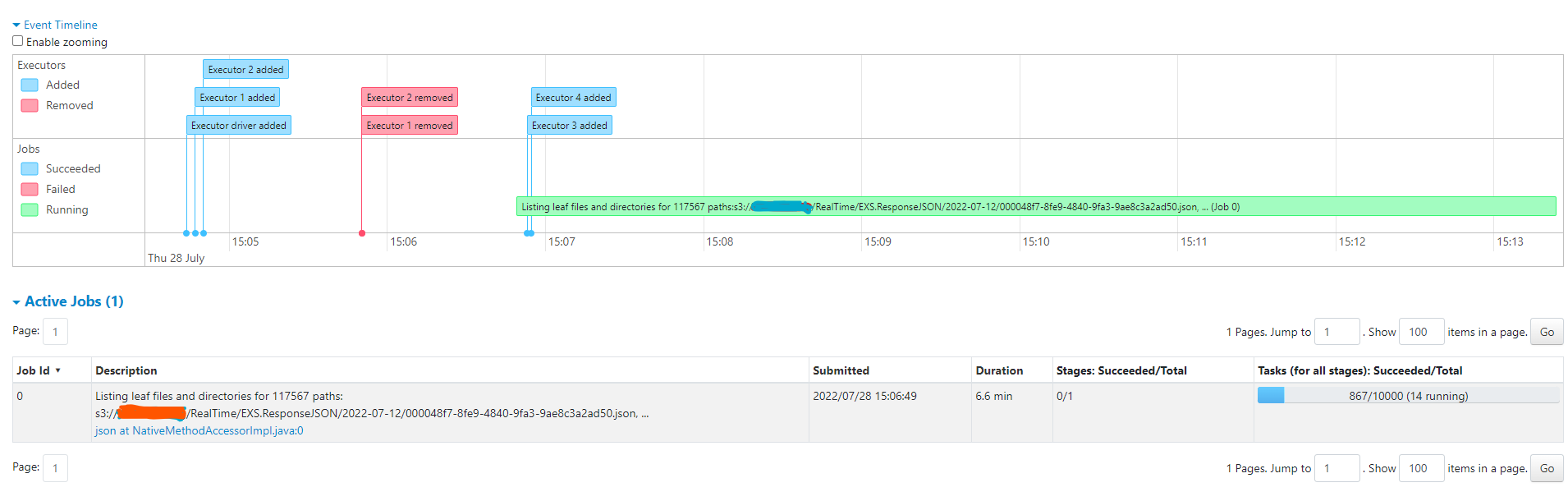
As you can see only a single job with a single task is created to list and
fetch all the s3 files (as expected according to Spark Docs/Architecture).
Until the listing is completed there will be a single task running.
I have shared some suggestions in my original question so we can avoid and
improve the Hudi S3EventSource implementation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}