ngonik opened a new issue #5036: URL: https://github.com/apache/hudi/issues/5036
**Describe the problem you faced** I'm using AWS DMS to export CDC data from a Postgres DB to S3. For tables where I only do Inserts and Updates I don't have any issues, my problem happens when trying to delete rows. Checking my logs I see the problem arises because the precombine key is null on the data I have on S3. Checking the data I see the following: 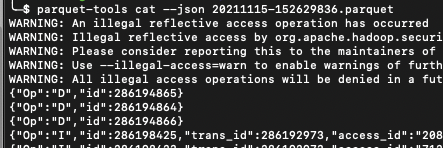 My delete operations only contain the PK id and nothing else. I tried looking at AWS docs to see if there's any config option to change this and bring all the data of the row (like you can see in these docs: [link](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Target.S3.html)) but unluckily got no answers. Does anyone know if there's a config that would make this work? If not, how can I handle these deletes with Hudi only using the PK? * Hudi version : 0.7.0 * Spark version : 2.4.7 * Hive version : 2.3.7 * Hadoop version : * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no **Additional context** DMS Engine Version: 3.4.5 **Stacktrace** ```22/03/09 12:32:07 INFO Client: client token: N/A diagnostics: User class threw exception: org.apache.hudi.exception.HoodieUpsertException: Failed to upsert for commit time 20220309123202 at org.apache.hudi.table.action.commit.AbstractWriteHelper.write(AbstractWriteHelper.java:62) at org.apache.hudi.table.action.commit.SparkUpsertCommitActionExecutor.execute(SparkUpsertCommitActionExecutor.java:46) at org.apache.hudi.table.HoodieSparkCopyOnWriteTable.upsert(HoodieSparkCopyOnWriteTable.java:92) at org.apache.hudi.table.HoodieSparkCopyOnWriteTable.upsert(HoodieSparkCopyOnWriteTable.java:82) at org.apache.hudi.client.SparkRDDWriteClient.upsert(SparkRDDWriteClient.java:146) at org.apache.hudi.utilities.deltastreamer.DeltaSync.writeToSink(DeltaSync.java:427) at org.apache.hudi.utilities.deltastreamer.DeltaSync.syncOnce(DeltaSync.java:278) at org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer.lambda$sync$2(HoodieDeltaStreamer.java:170) at org.apache.hudi.common.util.Option.ifPresent(Option.java:96) at org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer.sync(HoodieDeltaStreamer.java:168) at org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer.main(HoodieDeltaStreamer.java:470) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:688) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 10 in stage 3.0 failed 4 times, most recent failure: Lost task 10.3 in stage 3.0 (TID 18, ip-172-31-83-103.ec2.internal, executor 6): org.apache.hudi.exception.HoodieException: The value of updated_at can not be null at org.apache.hudi.avro.HoodieAvroUtils.getNestedFieldVal(HoodieAvroUtils.java:436) at org.apache.hudi.utilities.deltastreamer.DeltaSync.lambda$readFromSource$d62e16$1(DeltaSync.java:389) at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040) at scala.collection.Iterator$$anon$11.next(Iterator.scala:410) at scala.collection.Iterator$$anon$11.next(Iterator.scala:410) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:64) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:95) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2136) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2124) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2123) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2123) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:994) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:994) at scala.Option.foreach(Option.scala:257) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:994) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2384) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2333) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2322) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:805) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2097) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2118) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2137) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2162) at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:385) at org.apache.spark.rdd.RDD.collect(RDD.scala:989) at org.apache.spark.rdd.PairRDDFunctions$$anonfun$countByKey$1.apply(PairRDDFunctions.scala:370) at org.apache.spark.rdd.PairRDDFunctions$$anonfun$countByKey$1.apply(PairRDDFunctions.scala:370) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:385) at org.apache.spark.rdd.PairRDDFunctions.countByKey(PairRDDFunctions.scala:369) at org.apache.spark.api.java.JavaPairRDD.countByKey(JavaPairRDD.scala:312) at org.apache.hudi.index.bloom.SparkHoodieBloomIndex.lookupIndex(SparkHoodieBloomIndex.java:114) at org.apache.hudi.index.bloom.SparkHoodieBloomIndex.tagLocation(SparkHoodieBloomIndex.java:84) at org.apache.hudi.index.bloom.SparkHoodieBloomIndex.tagLocation(SparkHoodieBloomIndex.java:60) at org.apache.hudi.table.action.commit.AbstractWriteHelper.tag(AbstractWriteHelper.java:69) at org.apache.hudi.table.action.commit.AbstractWriteHelper.write(AbstractWriteHelper.java:51) ... 15 more Caused by: org.apache.hudi.exception.HoodieException: The value of updated_at can not be null at org.apache.hudi.avro.HoodieAvroUtils.getNestedFieldVal(HoodieAvroUtils.java:436) at org.apache.hudi.utilities.deltastreamer.DeltaSync.lambda$readFromSource$d62e16$1(DeltaSync.java:389) at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040) at scala.collection.Iterator$$anon$11.next(Iterator.scala:410) at scala.collection.Iterator$$anon$11.next(Iterator.scala:410) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:64) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:95) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750)``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}