sweco commented on issue #19329:
URL: https://github.com/apache/airflow/issues/19329#issuecomment-967199405
# Steps to reproduce
1. Prepare a relatively small cluster, e.g. 1 node with 8 GB of RAM.
2. Deploy Airflow using Kubernetes executor there.
3. Prepare a DAG according to the following specification
- It tries to run 5 tasks concurrently
- Each task specifies 2 GB of RAM in their pod requests - i.e. the sum
of requested RAM is greater than the total available RAM (5 * 2 GB = 10 GB > 8
GB)
- Each task is taking more than 300 seconds (the scheduler does not
crash immediately after 300 seconds, so be sure to put some reserve, e.g. 600
seconds)
```python
t1 = []
for i in range(5):
t = BashOperator(
task_id=f't1_{i}',
bash_command='sleep 600 && echo Hello World!',
executor_config={
'pod_override': k8s.V1Pod(
spec=k8s.V1PodSpec(
containers=[
k8s.V1Container(
name="base",
resources=k8s.V1ResourceRequirements(
requests={
'memory': '2000Mi',
'cpu': '1000m'
}
)
)
]
)
)
}
)
t1.append(t)
t2 = BashOperator(
task_id='t2',
bash_command='sleep 20 && date',
)
t1 >> t2
```
4. Run the DAG, you should see that at least one of the tasks' pods will not
be able to be run and will thus be in `Pending` state.

5. After ~6 minutes the pods will be deleted by the scheduler, marked as
`up_for_retry` and at the same time `t2` will be marked as `upstream_failed`.
The scheduler reports this error log for each task:
```
ERROR - Pod "internaltestt1..." has been pending for longer than 300
seconds.It will be deleted and set to failed.
```
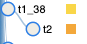
In the next screenshot we can see the upstream task, whose pod was
deleted, marked as `up_for_retry` and `t2` marked as `upstream_failed` even
though the upstream task can still succeed running on the second try.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}