Hi Frank, thanks for the input. Im still a bit sceptical to be honest that this is all, since a.) our bench values are pretty stable over time (natilus times and octopus times) with a variance of maybe 20% which i would put on normal cluster load.
Furthermore the HDD pool also halved its performance and the IO waitstates also halved and the raw OSD IO Utilisation dropped by 50% since the update. From old testings (actually done with FIO) i still see, that in our old setup (10GE only) we could achieve 310k IOPS on NVME only test storage and our current SSD’s do around 35k per Disk, so i guess we should be able to reach higher values than we do right now with enough clients. i need to know if there is a proper explanation for the waitstates vs. performance drop… ;-) Cheers Kai > On 7 Dec 2021, at 12:57, Frank Schilder <fr...@dtu.dk> wrote: > > Hi, > > I also executed some benchmarks on RBD and found that the ceph built-in > benchmark commands were both, way too optimistic and highly unreliable. > Successive executions of the same command (say, rbd bench for a 30 minute > interval) would give results with factor 2-3 between averages. I moved to use > fio, which gave consistent, realistic and reproducible results. > > I vaguely remember that there was a fix for this behaviour in the OSD code > quite some time ago. I believe there was a caching issue that was in the way > of realistic results. It might be due to this fix that you now see realistic > IOP/s instead of wishful thinking IOP/s. It might be possible that your > earlier test results were a factor of 2 too optimistic and your current > results are the right ones. The factor 2 you see is what I saw between rbd > bench and fio with rbd engine (fio was factor 2 lower). > > Best regards, > ================= > Frank Schilder > AIT Risø Campus > Bygning 109, rum S14 > > ________________________________________ > From: c...@komadev.de <mailto:c...@komadev.de> <c...@komadev.de > <mailto:c...@komadev.de>> > Sent: 07 December 2021 11:55:38 > To: Dan van der Ster > Cc: Ceph Users > Subject: [ceph-users] Re: 50% IOPS performance drop after upgrade from > Nautilus 14.2.22 to Octopus 15.2.15 > > Hi Dan, Josh, > > thanks for the input, bluefs_buffered_io with true and false, no real > differences to be seen (hard to say in a productive cluster. maybe some > little percent). > > We now disabled the write cache on our SSD’s and see a “felt” increase of the > performance up to 17k IOPS with 4k blocks but still far from the original > values, anyway thanks! ;-) > > For the 1024 bytes i think at some point we also wanted to test network > latencies, but i agree, using 4k is the default minimum. > > Attached you can find the links to the IO of the boxes i referenced in the > first mail, still new to good old mailing lists ;-) > > The IOPS Graph is the most significant, the IO waitstates of the system > dropped by nearly 50% which is the reason for our drop in IOPS overall i > think. just no clue why… (Update was on the 10th of Nov). i guess i want > these waitstates back :-o > > https://kai.freshx.de/img/ceph-io.png <https://kai.freshx.de/img/ceph-io.png> > <https://kai.freshx.de/img/ceph-io.png > <https://kai.freshx.de/img/ceph-io.png>> > > The latencies of some disks (OSD.12 is a small SSD (1.5TB) OSD.15 a big one > (7TB)) but here i guess that the big one gets 4 times more IOPS because of > its weight in CEPH > > https://kai.freshx.de/img/ceph-lat.png > > Cheers Kai > >> On 6 Dec 2021, at 18:12, Dan van der Ster <d...@vanderster.com> wrote: >> >> Hi, >> >> It's a bit weird that you benchmark 1024 bytes -- or is that your >> realistic use-case? >> This is smaller than the min alloc unit for even SSDs, so will need a >> read/modify/write cycle to update, slowing substantially. >> >> Anyway, since you didn't mention it, have you disabled the write cache >> on your drives? See >> https://docs.ceph.com/en/latest/start/hardware-recommendations/#write-caches >> for the latest related docs. >> >> -- Dan >> >> >> >> >> >> On Mon, Dec 6, 2021 at 5:28 PM <c...@komadev.de> wrote: >>> >>> Dear List, >>> >>> until we upgraded our cluster 3 weeks ago we had a cute high performing >>> small productive CEPH cluster running Nautilus 14.2.22 on Proxmox 6.4 >>> (Kernel 5.4-143 at this time). Then we started the upgrade to Octopus >>> 15.2.15. Since we did an online upgrade, we stopped the autoconvert with >>> >>> ceph config set osd bluestore_fsck_quick_fix_on_mount false >>> >>> but followed up the OMAP conversion after the complete upgrade step by step >>> by restarting one OSD after the other. >>> >>> Our Setup is >>> 5 x Storage Node, each : 16 x 2.3GHz, 64GB RAM, 1 x SSD OSD 1.6TB, 1 x >>> 7.68TB (both WD Enterprise, SAS-12), 3 HDD OSD (10TB, SAS-12) with Optane >>> Cache) >>> 4 x Compute Nodes >>> 40 GE Storage network (Mellanox Switch + Mellanox CX354 40GE Dual Port >>> Cards, Linux OSS drivers) >>> 10 GE Cluster/Mgmt Network >>> >>> Our performance before the upgrade, Ceph 14.2.22 (about 36k IOPS on the SSD >>> Pool) >>> >>> ### SSD Pool on 40GE Switches >>> # rados bench -p SSD 30 -t 256 -b 1024 write >>> hints = 1 >>> Maintaining 256 concurrent writes of 1024 bytes to objects of size 1024 for >>> up to 30 seconds or 0 objects >>> ... >>> Total time run: 30.004 >>> Total writes made: 1094320 >>> Write size: 1024 >>> Object size: 1024 >>> Bandwidth (MB/sec): 35.6177 >>> Stddev Bandwidth: 4.71909 >>> Max bandwidth (MB/sec): 40.7314 >>> Min bandwidth (MB/sec): 21.3037 >>> Average IOPS: 36472 >>> Stddev IOPS: 4832.35 >>> Max IOPS: 41709 >>> Min IOPS: 21815 >>> Average Latency(s): 0.00701759 >>> Stddev Latency(s): 0.00854068 >>> Max latency(s): 0.445397 >>> Min latency(s): 0.000909089 >>> Cleaning up (deleting benchmark objects) >>> >>> Our performance after the update CEPH 15.2.15 (drops to max 17k IOPS on the >>> SSD Pool) >>> # rados bench -p SSD 30 -t 256 -b 1024 write >>> hints = 1 >>> Maintaining 256 concurrent writes of 1024 bytes to objects of size 1024 for >>> up to 30 seconds or 0 objects >>> ... >>> Total time run: 30.0146 >>> Total writes made: 468513 >>> Write size: 1024 >>> Object size: 1024 >>> Bandwidth (MB/sec): 15.2437 >>> Stddev Bandwidth: 0.78677 >>> Max bandwidth (MB/sec): 16.835 >>> Min bandwidth (MB/sec): 13.3184 >>> Average IOPS: 15609 >>> Stddev IOPS: 805.652 >>> Max IOPS: 17239 >>> Min IOPS: 13638 >>> Average Latency(s): 0.016396 >>> Stddev Latency(s): 0.00777054 >>> Max latency(s): 0.140793 >>> Min latency(s): 0.00106735 >>> Cleaning up (deleting benchmark objects) >>> Note : OSD.17 is out on purpose >>> # ceph osd tree >>> ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF >>> -1 208.94525 root default >>> -3 41.43977 host xx-ceph01 >>> 0 hdd 9.17380 osd.0 up 1.00000 1.00000 >>> 5 hdd 9.17380 osd.5 up 1.00000 1.00000 >>> 23 hdd 14.65039 osd.23 up 1.00000 1.00000 >>> 7 ssd 1.45549 osd.7 up 1.00000 1.00000 >>> 15 ssd 6.98630 osd.15 up 1.00000 1.00000 >>> -5 41.43977 host xx-ceph02 >>> 1 hdd 9.17380 osd.1 up 1.00000 1.00000 >>> 4 hdd 9.17380 osd.4 up 1.00000 1.00000 >>> 24 hdd 14.65039 osd.24 up 1.00000 1.00000 >>> 9 ssd 1.45549 osd.9 up 1.00000 1.00000 >>> 20 ssd 6.98630 osd.20 up 1.00000 1.00000 >>> -7 41.43977 host xx-ceph03 >>> 2 hdd 9.17380 osd.2 up 1.00000 1.00000 >>> 3 hdd 9.17380 osd.3 up 1.00000 1.00000 >>> 25 hdd 14.65039 osd.25 up 1.00000 1.00000 >>> 8 ssd 1.45549 osd.8 up 1.00000 1.00000 >>> 21 ssd 6.98630 osd.21 up 1.00000 1.00000 >>> -17 41.43977 host xx-ceph04 >>> 10 hdd 9.17380 osd.10 up 1.00000 1.00000 >>> 11 hdd 9.17380 osd.11 up 1.00000 1.00000 >>> 26 hdd 14.65039 osd.26 up 1.00000 1.00000 >>> 6 ssd 1.45549 osd.6 up 1.00000 1.00000 >>> 22 ssd 6.98630 osd.22 up 1.00000 1.00000 >>> -21 43.18616 host xx-ceph05 >>> 13 hdd 9.17380 osd.13 up 1.00000 1.00000 >>> 14 hdd 9.17380 osd.14 up 1.00000 1.00000 >>> 27 hdd 14.65039 osd.27 up 1.00000 1.00000 >>> 12 ssd 1.45540 osd.12 up 1.00000 1.00000 >>> 16 ssd 1.74660 osd.16 up 1.00000 1.00000 >>> 17 ssd 3.49309 osd.17 up 0 1.00000 >>> 18 ssd 1.74660 osd.18 up 1.00000 1.00000 >>> 19 ssd 1.74649 osd.19 up 1.00000 1.00000 >>> >>> # ceph osd df >>> ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META >>> AVAIL %USE VAR PGS STATUS >>> 0 hdd 9.17380 1.00000 9.2 TiB 2.5 TiB 2.4 TiB 28 MiB 5.0 GiB >>> 6.6 TiB 27.56 0.96 88 up >>> 5 hdd 9.17380 1.00000 9.2 TiB 2.6 TiB 2.5 TiB 57 MiB 5.1 GiB >>> 6.6 TiB 27.89 0.98 89 up >>> 23 hdd 14.65039 1.00000 15 TiB 3.9 TiB 3.8 TiB 40 MiB 7.2 GiB >>> 11 TiB 26.69 0.93 137 up >>> 7 ssd 1.45549 1.00000 1.5 TiB 634 GiB 633 GiB 33 MiB 1.8 GiB >>> 856 GiB 42.57 1.49 64 up >>> 15 ssd 6.98630 1.00000 7.0 TiB 2.6 TiB 2.6 TiB 118 MiB 5.9 GiB >>> 4.4 TiB 37.70 1.32 272 up >>> 1 hdd 9.17380 1.00000 9.2 TiB 2.4 TiB 2.3 TiB 31 MiB 4.7 GiB >>> 6.8 TiB 26.04 0.91 83 up >>> 4 hdd 9.17380 1.00000 9.2 TiB 2.6 TiB 2.5 TiB 28 MiB 5.2 GiB >>> 6.6 TiB 28.51 1.00 91 up >>> 24 hdd 14.65039 1.00000 15 TiB 4.0 TiB 3.9 TiB 38 MiB 7.2 GiB >>> 11 TiB 27.06 0.95 139 up >>> 9 ssd 1.45549 1.00000 1.5 TiB 583 GiB 582 GiB 30 MiB 1.6 GiB >>> 907 GiB 39.13 1.37 59 up >>> 20 ssd 6.98630 1.00000 7.0 TiB 2.5 TiB 2.5 TiB 81 MiB 7.4 GiB >>> 4.5 TiB 35.45 1.24 260 up >>> 2 hdd 9.17380 1.00000 9.2 TiB 2.4 TiB 2.3 TiB 26 MiB 4.8 GiB >>> 6.8 TiB 26.01 0.91 83 up >>> 3 hdd 9.17380 1.00000 9.2 TiB 2.7 TiB 2.6 TiB 29 MiB 5.4 GiB >>> 6.5 TiB 29.38 1.03 94 up >>> 25 hdd 14.65039 1.00000 15 TiB 4.2 TiB 4.1 TiB 41 MiB 7.7 GiB >>> 10 TiB 28.79 1.01 149 up >>> 8 ssd 1.45549 1.00000 1.5 TiB 637 GiB 635 GiB 34 MiB 1.7 GiB >>> 854 GiB 42.71 1.49 65 up >>> 21 ssd 6.98630 1.00000 7.0 TiB 2.5 TiB 2.5 TiB 96 MiB 7.5 GiB >>> 4.5 TiB 35.49 1.24 260 up >>> 10 hdd 9.17380 1.00000 9.2 TiB 2.2 TiB 2.1 TiB 26 MiB 4.5 GiB >>> 7.0 TiB 24.21 0.85 77 up >>> 11 hdd 9.17380 1.00000 9.2 TiB 2.5 TiB 2.4 TiB 30 MiB 5.0 GiB >>> 6.7 TiB 27.24 0.95 87 up >>> 26 hdd 14.65039 1.00000 15 TiB 3.6 TiB 3.5 TiB 37 MiB 6.6 GiB >>> 11 TiB 24.64 0.86 127 up >>> 6 ssd 1.45549 1.00000 1.5 TiB 572 GiB 570 GiB 29 MiB 1.5 GiB >>> 918 GiB 38.38 1.34 57 up >>> 22 ssd 6.98630 1.00000 7.0 TiB 2.3 TiB 2.3 TiB 77 MiB 7.0 GiB >>> 4.7 TiB 33.23 1.16 243 up >>> 13 hdd 9.17380 1.00000 9.2 TiB 2.4 TiB 2.3 TiB 25 MiB 4.8 GiB >>> 6.8 TiB 26.07 0.91 84 up >>> 14 hdd 9.17380 1.00000 9.2 TiB 2.3 TiB 2.2 TiB 54 MiB 4.6 GiB >>> 6.9 TiB 25.13 0.88 80 up >>> 27 hdd 14.65039 1.00000 15 TiB 3.7 TiB 3.6 TiB 54 MiB 6.9 GiB >>> 11 TiB 25.55 0.89 131 up >>> 12 ssd 1.45540 1.00000 1.5 TiB 619 GiB 617 GiB 163 MiB 2.3 GiB >>> 871 GiB 41.53 1.45 63 up >>> 16 ssd 1.74660 1.00000 1.7 TiB 671 GiB 669 GiB 23 MiB 2.2 GiB >>> 1.1 TiB 37.51 1.31 69 up >>> 17 ssd 3.49309 0 0 B 0 B 0 B 0 B 0 B >>> 0 B 0 0 0 up >>> 18 ssd 1.74660 1.00000 1.7 TiB 512 GiB 509 GiB 18 MiB 2.3 GiB >>> 1.2 TiB 28.62 1.00 52 up >>> 19 ssd 1.74649 1.00000 1.7 TiB 709 GiB 707 GiB 64 MiB 2.0 GiB >>> 1.1 TiB 39.64 1.39 72 up >>> TOTAL 205 TiB 59 TiB 57 TiB 1.3 GiB 128 GiB >>> 147 TiB 28.60 >>> MIN/MAX VAR: 0.85/1.49 STDDEV: 6.81 >>> >>> >>> What we have done so far (no success) >>> >>> - reformat two of the SSD OSD's (one was still from luminos, non LVM) >>> - set bluestore_allocator from hybrid back to bitmap >>> - set osd_memory_target to 6442450944 for some of the SSD OSDs >>> - cpupower idle-set -D 11 >>> - bluefs_buffered_io to true >>> - disabled default firewalls between CEPH nodes (for testing only) >>> - disabled apparmor >>> - added memory (runs now on 128GB per Node) >>> - upgraded OS, runs now on kernel 5.13.19-1 >>> >>> What we observe >>> - HDD Pool has similar behaviour >>> - load is higher since update, seems like more CPU consumption (see >>> graph1), migration was on 10. Nov, around 10pm >>> - latency on the "big" 7TB SSD's (i.e. OSD.15) is significantly higher than >>> on the small 1.6TB SSDs (OSD.12), see graph2, must be due to the higher >>> weight though >>> - load of OSD.15 is 4 times higher than load of OSD.12, must be due to the >>> higher weight though as well >>> - start of OSD.15 (the 7TB SSD's is significantly slower (~10 sec) compared >>> to the 1.6TB SSDs >>> - increasing the block size in the benchmark to 4k, 8k or even 16k >>> increases the throughput but keeps the IOPS more or less stable, the drop >>> at 32k is minimal to ~14k IOPS in average >>> >>> We already checked the ProxMoxx List without any remedies yet and we are a >>> bit helpless, any suggestions and / or does someone else has similar >>> experiences? >>> >>> We are a bit hesitant to upgrade to Pacific, given the current situation. >>> >>> Thanks, >>> >>> Kai >>> >>> >>> >>> >>> >>> >>> >>> >>> >>> _______________________________________________ >>> ceph-users mailing list -- ceph-users@ceph.io >>> To unsubscribe send an email to ceph-users-le...@ceph.io > > _______________________________________________ > ceph-users mailing list -- ceph-users@ceph.io <mailto:ceph-users@ceph.io> > To unsubscribe send an email to ceph-users-le...@ceph.io > <mailto:ceph-users-le...@ceph.io> _______________________________________________ ceph-users mailing list -- ceph-users@ceph.io To unsubscribe send an email to ceph-users-le...@ceph.io
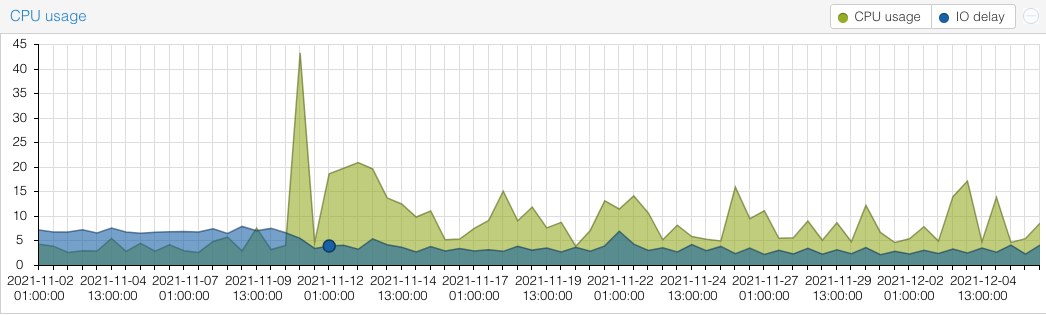{kind=link}
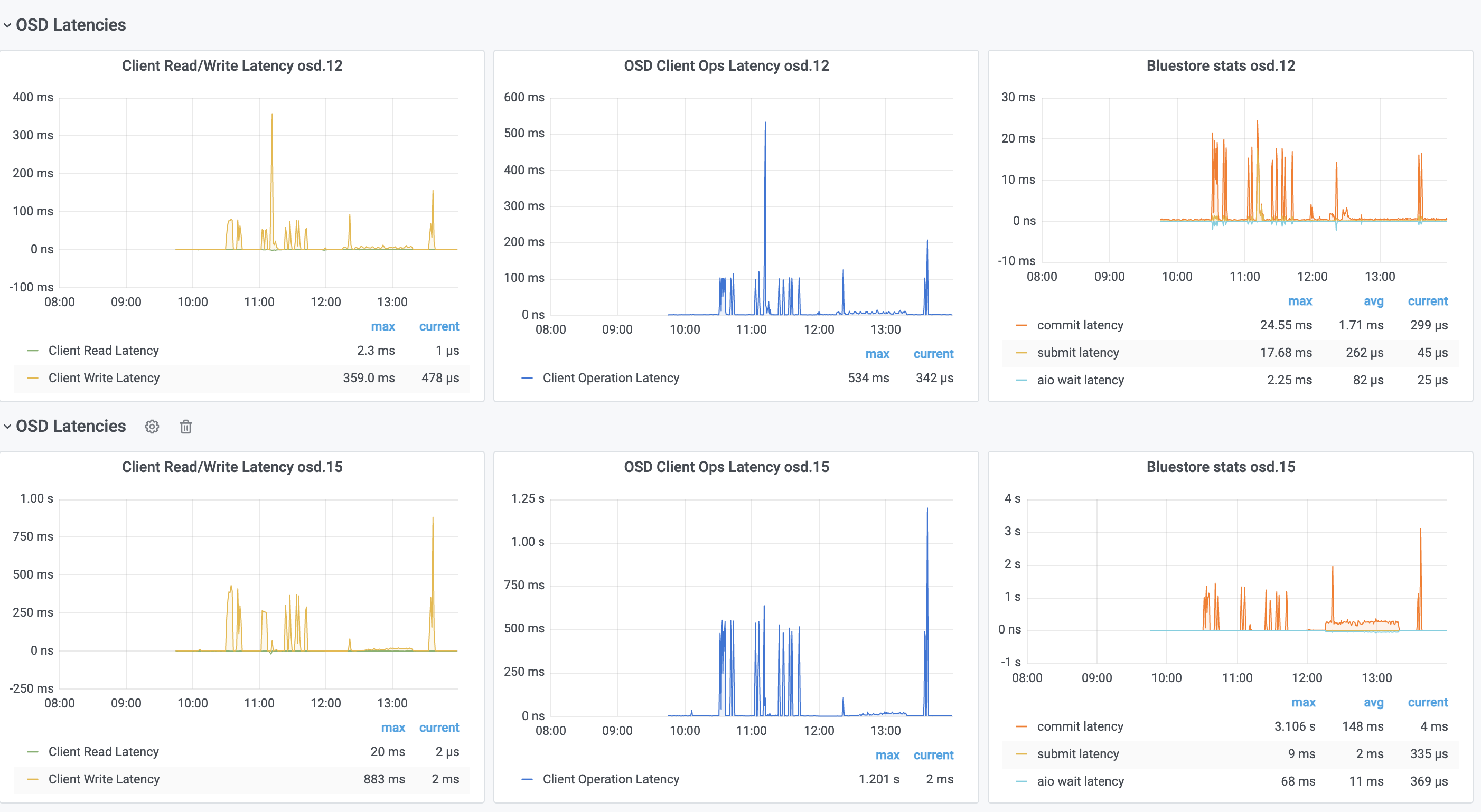{kind=link}